FILESTREAM w Sql Server
Czym jest FILESTREAM
FILESTREAM pojawił się w SQL Server 2008 i był odpowiedzią na pojawiającą sie potrzebę przechowywania dużych plików. Duże pliki to duże wyzwanie dla bazy danych - przetwarzanie takich struktur jest zasobochłonne i czasochłonne, dostęp do takich danych realizowany jest nieco inaczej niż do zwykłych, mniejszych danych. Dane, nazwijmy je sobie małymi, przechowywane są w jednostce alokacji zwanej obszarem IN_ROW_DATA, pogrupowane w bloki (strony) po 8kB. Duże pliki (LOB - ang. large object) przechowywane są w obszarze zwanym LOB_DATA. Problem w tym, że te obszary nie leżą obok siebie, co więcej, nie da się zaindeksować obszarów LOB_DATADane LOB_DATA mogą się pojawiać jako dodatkowe kolumny dołączane do liści indeksu - opcja INCLUDE instrukcji CREATE INDEX.. Pojawia się problem ze stosowaniem odczytów wyprzedzających, SQL Server musi skakać po różnych obszarach pamięci. Co też nie jest bez znaczenia - rozmiar samej bazy danych zwiększa się z każdym takim obiektem. A jeżeli jest ich dużo...
Dotychczasowe rozwiązania problemu dużych plików
Jednym z rozwiązań było przechowywanie danych w postaci typu varbinary(MAX) (rzadziej varchar(MAX) lub nvarchar(MAX) dla dużych obiektów tekstowych) lub, wcześniej, w postaci typu image, text lub ntextTypy image, text i ntext, według dokumentacji, nie powinny być już używane. Uznane są za przestarzałe, a ich wsparcie motywowane jest jedynie względami zgodności wstecz.. Zaletą tego rozwiązania jest spójność (wszystko mamy w bazie) oraz pełna transakcyjność (dane binarne pliku zapisywane są razem z innymi danymi). Łatwo także zarządzać tymi danymi, wykonywać zapytania, łatwo też zrobić kopię zapasową - wszystko jest w tabelach i kolumnach bazy danych. Wadą rozwiązania jest wydajność. Pliki binarne muszą być odczytane w całości, przesyłane są w całości, muszą być przez jakiś czas przechowywane w całości w pamięci operacyjnej.
Drugim powszechnie stosowanym rozwiązaniem było przechowywanie w bazie tylko lokalizatora, a same dane lądowały w systemie plików systemu operacyjnego. Ten lokalizator to na przykład ścieżka do pliku, globalny identyfikator, który stawał się kodową nazwą danej binarnej przechowywanej w konkretnym katalogu, widzialem też rozwiązanie, w którym nazwy plików przyjmowały kolejne wartości IDENTITY (pliki miały nazwy 1, 2, 3 itd.). Rozwiązanie ma swoje zalety. Po pierwsze, system plików systemu operacyjnego przystosowany jest do przechowywania... plików. Inaczej mówiąc dowolnych danych binarnych, różnych rozmiarów. Do obsługi tych plików powstało rozbudiwane API, metody strumieniowego odczytu, dzięki czemu dane mogą być odczytywane i przesyłane partiami. W tym rozwiązaniu dane binarne leżą obok bazy danych. Rozwiązanie nie jest jednak pozbawione wad. Po pierwsze, trudno zapewnić transakcyjność - operacje w bazie muszą być synchronizowane z operacjami w systemie plików. Kolejny problem to tworzenie kopii zapasowych (BACKUP) i przywracanie (RESTORE) - pliki w systemie operacyjnym nie podlegają tym operacjom. Kolejny problem to zapewnienie bezpieczeństwa. Pliki na dysku można odczytywać, modyfikować i usuwać, a sama baza nic o tym nie wie. W praktyce dość szybko pojawiają się rozbieżności między stanem w bazie, a stanem w systemie plików.
Pojawienie się FILESTREAM
Celem FILESTREAM było jak najlepsze połączenie obu wspomnianych wyżej technik. Z jednej strony dane binarne przechowywane są w systemie plików systemu operacyjnego, z drugiej zaś, wszystko przechodzi przez bazę danych. Dzięki temu dane są spójne, a operacje zapisu i modyfikacji podlegają transakcjom. Dane zapisane są w systemie plików, ale można na nich wykonywać zwykłe zapytania! Pełna integracja!
Część operacji, które wykonywał SQL Server zostało przerzuconych na system operacyjny. Wiadomo, że nie powinno się powielać mechanizmów na różnych warstwach. Skoro system operacyjny ma mechanizmy buforowania, SQL Server może je pominąć. Nie ma potrzeby buforować dwa razy tych samych danych. SQL Server ma i tak dużo zadań.
FILESTREAM nie jest interesującym rozwiązaniem ze względu na buforowanie. Sama nazwa zdradza, że jest to możliwość strumieniowego przesyłania danych (ang. stream - strumień). I te, znane już od bardzo, bardzo dawna, strumienie zostały teraz zintegrowane z SQL Server. Nowe możliwości powstałe w wyniku pojawienia się FILESTREAM wymusiły rozbudowę SQL Server i T-SQL. Pojawiły się nowe konstrukcje językowe i instrukcje.
Włączanie usługi FILESTREAM
Usługę FILESTREAM można włączyć podczas instalacji, ale można to też zrobić później. Należy w tym celu otworzyć SQL Server Configuration Manager, wybrać SQL Server Services, a tam, dla wybranej instancji kliknąć właściwości. Konfiguracja FILESTREAM znajduje się na zakładce... FILESTREAM.
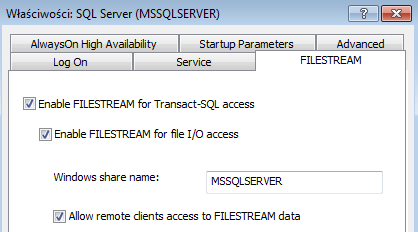
Rys 1. Okno konfiguracji FILESTREAM dla serwera.
Oprócz konfiguracji globalnej, dla serwera, jest jeszcz konfiguracja na poziomie bazy danych. W SQL Management Studio należy przejść do właściwości bazy danych, a tam, w sekcji Options, w grupie FILESTREAM, znajdują się dodatkowe właściwości.
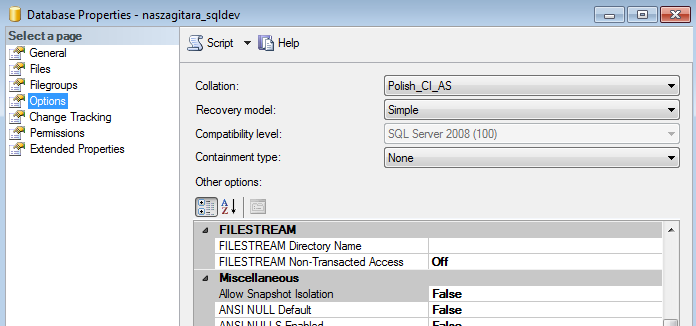
Rys 1. Okno konfiguracji FILESTREAM dla bazy danych.
Sama konfiguracja dla bazy danych może być również wykonana z poziomu T-SQL:
GO
RECONFIGURE
GO
Cyferka będąca drugim parametrem oznacza poziom dostępu. 0 oznacza brak dostępu, 1 - transakcyjny dostęp z poziomu SQL, 2 - pełen dostęp. Opcja druga oznacza możliwość dostępu do plików FILESTREAM z poziomu strumieniowego API Windows. To z kolei pozwala przetwarzać pliki z bazy danych tymi samymi metodami co wszystkie inne pliki w systemie operacyjnym.
Tworzenie bazy danych z obsługą FILESTREAM
Liczba czynności, które należy wykonać jest długa, ale już zbliżamy się do końca. Tworzenie bazy z obsługą FILESTREAM różni się w zasadzie tylko tym, że należy stworzyć dodatkową grupę plików z atrybutem FILESTREAM. Przyjrzyjmy się poniższemu skryptowi:
(
NAME = N'FileStreamTest',
FILENAME = N'D:\FileStreamTest.mdf'
),
FILEGROUP FileStreamTest_Files CONTAINS FILESTREAM
(
NAME = N'FileStreamTest_Files',
FILENAME = N'D:\FileStreamTest_Files'
)
LOG ON
(
NAME = N'FileStreamTest_log',
FILENAME = N'D:\FileStreamTest_log.ldf'
)
Element, który wyróżnia konfigurację bazy z grupą FILESTREAM od konfiguracji zwykłej bazy, został pogrubiony. To w zasadzie wszystko co jest nam potrzebne. Można przystąpić do definiowania tabel.
Tworzenie tabel z kolumną FILESTREAM
Tabela, która będzie zawierała kolumnę z atrybutem FILESTREAM musi spełniać trzy reguły:
- Tabela musi posiadać unikatową kolumnę (może to być klucz główny) oraz
- Kolumna musi być typu UNIQUEIDENTIFIER z ograniczeniem NOT NULL oraz
- Kolumna musi posiadać atrybut ROWGUIDCOL.
Przyjrzyjmy się zatem minimalistycznej wersji pokazanej na poniższym listingu:
(
PlikUid UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL,
Binaries varbinary(MAX) FILESTREAM NULL,
CONSTRAINT PK_Pliki
PRIMARY KEY CLUSTERED (PlikUid)
)
To w zasadzie tyle. Można już wstawiać, modyfikować, usuwać i pobierać dane.
SELECT, INSERT, UPDATE I DELETE na FILESTREAM
Język SQL jest logiczną nakładką na fizyczną reprezentacje zbiorów danych w postaci tabel. Ta logiczna warstwa T-SQL pozwala na wykonywanie wszystkich podstawowych operacji tak, jakby pod spodem znajdowała się zwykła kolumna, a nie plik na dysku w systemie operacyjnym. Przyjrzyjmy się kolejnym operacjom:
INSERT dbo.Pliki
VALUES (NEWID(), CAST('' AS varbinary(MAX)))
--Operacja INSERT
DECLARE @guid UNIQUEIDENTIFIER=NEWID()
INSERT dbo.Pliki
VALUES (@guid, CAST('A' AS varbinary(MAX)))
--Operacja UPDATE
UPDATE dbo.Pliki
SET Binaries=CAST('B' AS varbinary(MAX))
WHERE PlikUid=@guid
--Operacja DELETE (zapewne nic nie usunie)
DELETE FROM dbo.Pliki
WHERE PlikUid=NEWID()
--Operacja SELECT
SELECT * FROM dbo.Pliki
Myślę, że nie wymaga to wyjaśnień. Analizując treść zapytań nie można stwierdzić, że gdzieś tam pod spodem działa FILESTREAM. To jest w tym najlepsze.
Podsumowanie
Temat FILESTREAM jest rozległy i postaram się wkrótce go rozszerzyć. Warto wiedzieć, że te pliki gdzieś fizycznie leżą, warto wiedzieć, jak korzystać z tego strumienia jako prawdziwego strumienia. Jak przy pomocy ADO.NET korzystać z FILESTREAM, jak sobie z tym radzą biblioteki O/RM, jakie dodatkowe funkcje mamy do dyspozycji w T-SQL, a przede wszystkim, jak z tych dobrodziejstw korzystać właściwie, czyli strumieniowo. To wszystko są tematy, które wypadałoby rozwinąć. O tym jednak innym razem.
Kategoria:FILESTREAMSQL Server
Brak komentarzy - bądź pierwszy