Różnica między JOIN i LEFT JOIN
Operacja złączenia JOIN
Operacja złączenia wewnętrzego JOINPełna nazwa to INNER JOIN, ale jest to operacja tak popularna, że rozsądne było skrócenie tego do jednego tylko słowa kluczowego JOIN. Reasumując: INNER JOIN to to samo co JOIN. w algebrze relacyjnej odpowiada tzw. złączeniom Theta (θ). Wynikiem złącznia dwóch zbiorów A(a1, a2,...,an) i B(b1, b2,...,am), jest zbiór wszystkich par, C, zawierający każdy atrybut z obu zbiorów wejściowych, C(a1, a2,...,an, b1, b2,...,am) i spełniających predykat złączeniaPredykat należy rozumieć jako warunek złączenia, podawany w sekcji ON i mogący zwierać praktycznie dowolne warunki logiczne..
Można takie złączenie zdefiniować nieco inaczej, programistycznie. Złączenie A JOIN B ON W, gdzie A, B to zbiory wejściowe, W to dowolny warunek, możemy wyliczyć następująco:
Dla każdego wiersza (a1, a2,...,an) ze zbioru A:
Dla każdego wiersza (b1, b2,...,am) ze zbioru B:
Jeżeli spełniony jest warunek W(A, B)
Zwróć (a1, a2,...,an, b1, b2,...,am)
Powyższy algorytm jest raczej fizyczną implementacją niż definicją, ale pomaga zrozumieć ogólną zasadęJest to jedna z najprostszych metod implementacji, tzw. LOOP JOIN. Dwa inne popularne algorytmy to HASH JOIN i MERGE JOIN..
Jeszcze inną metodą pokazania złączenia jest konkretny przykład. Jest to jednocześnie moja ulubiona metoda. Popatrzmy na przykładowe dwie tabele reprezentujące pracownika i przypisane do niego zadania:
CREATE TABLE Employee ( ID int CONSTRAINT PK_Employee_ID PRIMARY KEY, FirstName nvarchar(20) NOT NULL, LastName nvarchar(20) NOT NULL ) INSERT Employee VALUES (1, 'Jan', 'Byk'), (2, 'Anna', 'Kot'), (3,'Ewa','Lis') CREATE TABLE Task ( ID int IDENTITY CONSTRAINT PK_Task_ID PRIMARY KEY, Name nvarchar(20) NOT NULL, Assignment int CONSTRAINT FK_Task_Employee FOREIGN KEY REFERENCES Employee(ID) ) INSERT Task VALUES ('Fix issue', 1),('Eat something',1),('Handle data', 3),('Do some stuff', NULL)
Oraz na złączenie:
SELECT E.FirstName, E.LastName, E.ID, T.Assignment, T.Name FROM Employee E JOIN Task T ON T.Assignment=E.ID
Wynikiem pokazanej operacji będzie taka oto tabela:
| FirstName | LastName | ID | Assignment | Name |
|---|---|---|---|---|
| Jan | Byk | 1 | 1 | Fix issue |
| Jan | Byk | 1 | 1 | Eat something |
| Ewa | Lis | 3 | 3 | Handle data |
Celowo pokazałem dwie kolumny złączenia obok siebie. Na nich operuje predykat. Jeżeli są równe, mamy dopasowanie. Anna Kot nie jest wyświetlana, bo nie ma zadania wskazującego na numer 2. Do some stuff również nie ma wskazania na żadniego z pracowników i też jest odrzucone. Jan Byk ma dwa dopasowania, dlatego dwa wiersze z Janem Bykiem pojawiły się w zbiorze wynikowym.
Warto przy okazji wspomnieć, że predykat nie musi się sprowadzać do porówniania. Może tam być dowolny inny operator (np. <, >, LIKE), może być całe wyrażenie logiczne z AND i OR oraz nawiasami, funkcja, a nawet podzapytanie.
LEFT JOIN i brak dopasowania
Zwykłe złączenie wewnętrzne (INNER JOIN) ma tę właściwość, że zwraca tylko pełne dopasowania. Gdybyśmy jednak chcieli zachować wszystkie rekordy z pierwszego zbioru, użylibyśmy złączenie zewnętrzego (OUTER JOIN), w tym przypadku lewego (LEFT OUTER JOIN lub skrótowo LEFT JOIN). Oznacza to, że żaden rekord z lewego zbioruLewy i prawy należy traktować wręcz dosłownie. Gdyby całe zapytanie mieściło się w jednej linii i czytalibyśmy od lewej do prawej, -prawość- i -lewość- stałyby się oczywiste. nie może być pominięty. Biznesowo odpowiada to na następujące pytanie: pokaż mi również te osoby, do których nie przypisano żadnego zadania. Jeżeli rekord z pierwszej tabeli nie ma żadnego dopasowania, uzupełniany jest wartościami NULL. Popatrzmy na przykład:
SELECT E.FirstName, E.LastName, E.ID, T.Assignment, T.Name FROM Employee E LEFT JOIN Task T ON T.Assignment=E.ID
Rezultat zaprezentowano poniżej:
| FirstName | LastName | ID | Assignment | Name |
|---|---|---|---|---|
| Jan | Byk | 1 | 1 | Fix issue |
| Jan | Byk | 1 | 1 | Eat something |
| Anna | Kot | 2 | NULL | NULL |
| Ewa | Lis | 3 | 3 | Handle data |
Kluczowy wiersz został wyróżniony. Anna Kot nie ma wprawdzie dopasowania, ale jej rekord został zachowany. To w zasadzie jedyna ważna różnica pomiędzy JOIN i LEFT JOIN.
W przypadku LEFT JOIN rekordy z pierwszego (lewego) zbioru zostaną zawsze zachowane. Bez względu na istnienie dopasowania w drugiej tabeli. Inaczej mówiąc - jeżeli dla rekordu z pierwszego zbioru nia ma żadnego rekordu w drugim zbiorze to:
- JOIN pominie ten wiersz,
- LEFT JOIN uzupełni wartościami NULL wszystkie kolumny reprezentujące atrybuty drugiego zbioru.
Liczność zbiorów
Z samej definicji jasno wynika, że liczba wierszy wynikowych operacji LEFT JOIN jest nie mniejsza liczba wierszy wynikowych operacji JOIN. Są to bowiem te same wiersze co w JOIN i jeszcze te, które nie mają odpowiednika w drugiej tabeli. Sprawia to, że zbiór może być nieco większy. To z kolei powoduje, że czas wykonywania operacji LEFT JOIN może być nieco dłuższy i zasadniczo tak jest*. Należy jednak pamiętać, że JOIN i LEFT JOIN to dwie zupełnie inne operacje logiczne i nie należy zamieniać ich w celu ograniczenia liczby wyników i uzyskania wzrostu wydajności. Jeżeli biznesowo rekordy niedopasowane są istotne, należy użyć LEFT JOIN.
Relacja symetryczna JOIN
W matematyce, również w obszarze operacji na zbiorach, definiuje się coś takiego jak relacja. Oznacza to związek między dwoma elementami. Te relacje mogą mieć różne ciekawe własności i pozwalają na zastosowanie pewnych przekształceń. Mówi się, że relacja jest symetryczna, jeżeli dla każdej pary (A, B) spełniającej tę relację, relacja jest też spełniona przez (B, A). Taką relacją jest np. porówanie liczb. Jeżeli a = b to możemy stwierdzić, że b = a. Przekładając to na operację JOIN mamy:
Jeżeli: A JOIN B = C To: B JOIN A = C
W praktyce oznacza to, że możemy sobie dowolnie zamieniać kolejność złączeń nie wpływając na końcowy rezultat. Co nam to daje? Ta z pozoru błaha właściwość pozwala optymalizatorowi przestawiać operacje złączenia i doprowadzić do znacznie wydajniejszej metody wykonania zapytania. Stwórzmy dwie tabele: jedna reprezentuje komputery (10000 rekordów), druga licencje (10 rekordów).
CREATE TABLE Computer ( ID int IDENTITY CONSTRAINT PK_Computer_ID PRIMARY KEY, Name nvarchar(20) NOT NULL ); CREATE TABLE License ( ID int IDENTITY CONSTRAINT PK_License_ID PRIMARY KEY, Name nvarchar(20) NOT NULL, Computer int CONSTRAINT FK_License_Computer FOREIGN KEY REFERENCES Computer(ID) ); CREATE TABLE N ( N int NOT NULL CONSTRAINT PK_N PRIMARY KEY ); WITH T10 AS (SELECT 1 N FROM (VALUES (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) T(N)) INSERT N SELECT ROW_NUMBER() OVER (ORDER BY (SELECT 0)) FROM T10 A CROSS JOIN T10 B CROSS JOIN T10 C CROSS JOIN T10 D INSERT Computer SELECT N'Computer '+CAST(N AS nvarchar(10)) FROM N INSERT License SELECT N'License'+CAST(N AS nvarchar(10)), N FROM N WHERE N<=10
Przyjrzyjmy się teraz prostemu zapytaniu:
SELECT * FROM Computer C JOIN License L ON L.Computer=C.ID
Można przeszukiwać rekody zgodnie z zapisaną instrukcją SQL, tj. dla każdego z 10000 komputerów wyszukać dopasowanie w 10 licencjach, ale może wydajniej byłoby zacząć poszukiwania od licencji dopasować komputer? Takie pytanie zadaje sobie optymalizator. Ponadto okazuje się, że wyszukiwanie komputera nie wymaga wykonania pełnej pętli jak w pokazanym na początku pseudoalgorytmie LOOP JOIN. Co więcej, po odwróceniu kolejności złączeń rekordy Computer możemy wyszukiwać po kluczu ID (a dokładniej indeksie automatycznie dla tego klucza założonym). To jeszcze bardziej zmniejsza koszt zapytania. Popatrzmy co zrobił optymalizator:

Popatrzmy dla kontrastu na to, co należałoby wykonać, gdyby tabele nie zostały zamienione miejscami:
SELECT * FROM Computer C JOIN License L ON L.Computer=C.ID OPTION (FORCE ORDER)
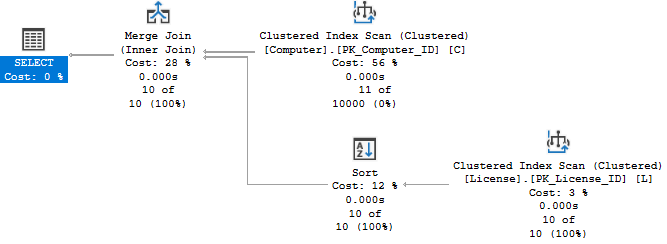
Warto zauważyć, że tym razem przeprowadzana jest operacja pełnego skanowania tabeli z komuterami i skromna operacja sortowania potrzebna do użycia złączenia typu MERGE JOIN. Same szacunki optymalizatora pokazują, że koszt tego drugiego planu jest o rząd wielkości wyższy.
Generalnie operacje JOIN dają znacznie więcej swobody i działają sprawniej niż operacje złączeń zewnętrznych (np. LEFT JOIN).
Czy JOIN zawsze jest szybszy niż LEFT JOIN?
Celowo pisząc o różnicy wydanościowej użyłem słów: "zasadniczo", "generalnie". Nie użyłem słowa "zawsze". Wygenerowanie optymalnego planu zapytania nie jest proste, bo wpływ na to ma wiele czynników. Rozmiary tabel, indeksy, rozkład wartości, liczba wierszy spełniających kryteria, ułożenie danych. Co więcej, optymalizator kończy pracę gdy uzna, że plan jest wystarczająco dobry. W przeciwnym razie samo opracowanie planu mogłoby trwać dłużej niż samo wykonanie zapytania. Popatrzmy na kilka przyładów pokazujących, że LEFT JOIN niekoniecznie musi być wolniejszy.
Relacja jeden do zero lub jeden
Pierwszy przykład pokazuje przekształcenie, jakie może być wykonane przez optymalizator w niektórych przypadkach. Wykorzystam te same tabele - Computer i License. Popatrzmy na przykład:
SELECT H.Name FROM License H JOIN Computer W ON H.Computer=W.ID SELECT H.Name FROM License H LEFT JOIN Computer W ON H.Computer=W.ID
Bardzo łatwo przegapić tutaj jeden szczegół, który został wychwycony przez optymalizator i doskonale widać to na planie wykonania:
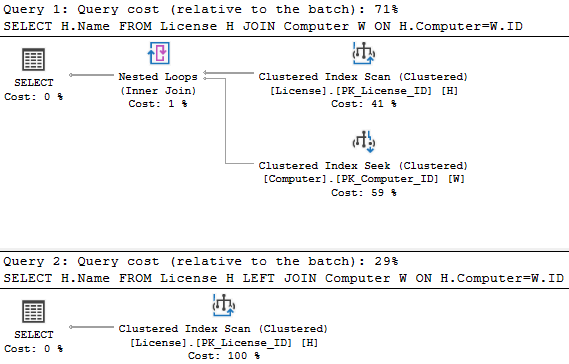
LEFT JOIN me tę ciekawą właściwość, że w przypadku relacji (jeden) do (jeden lub zero) zawsze zachowuje jeden i dokładnie jeden lewy wiersz. Jeżeli w prawej tabeli jest odpowienik - jest on dołączany, jeżeli nie ma - dołączane są wartości NULL. Lewa strona nie może zniknąć. Oznacza to, że, o ile nie potrzebujemy danych z drugiej tabeli, nie trzeba nawet wykonywać złączenia. Wydaje się, że jest to po prostu błąd w pisaniu zapytania. I w tym przypadku tak jest.
Co więcej, bardzo często taka systuacja nie jest spowodowana błędm technicznym. Do głowy przychodzą mi następujące sytuacje:
- Źródłem danych jest widok (VIEW), na którym wykonywana jest projekcja (wybranie tylko kilku koumn z bogatego zestawu dostępnego w widoku).
- Jest to zapytanie bazowe dla aplikacji, aplikacja decyduje, ile rzeczywiście kolumn chce pobrać decyduje o filtrowaniu i projekcji.
- Zapytanie generowane jest dynamicznie przez graficzny interfejs użytkownika, moduł raportowy itp. Również wtedy zapytania mogą być technicznie nieoptymalne.
Błędy w szacunkach optymalizatora
Innym przypadkiem, gdy złączenia zewnętrzne, m. in. LEFT JOIN, mogą się zachowywać lepiej, jest pobieranie ograniczonej liczby wierszy, np instrukcją TOPOgraniczenie liczby wierszy (Row Goal) może pojawić się również w innych przypadkach. Może to być np. intrukcja OFFSET/FETCH, IN, EXISTS, może to być wskazówka FAST N, wyrażenie SET ROWCOUNT, mogą to być bardziej złożone scenariusze z podzapytaniem wykorzystującym ROW_NUMBER i filtrem na tej wartości.. Odpada wtedy naturalna przewaga operacji JOIN, która z definicji kwalifikuje mniej (lub w najgorszym razie tyle samo) wierszy co LEFT JOIN.
Optymalizator może pozyskiwać informacje o liczebności z klilku źródeł. Pierwsze co przychodzi do głowy to statystyki, ale rozważmy oprócz tego kilka innych przypadków. Jeżeli na kolumnie założony jest klucz główny, możemy stwierdzić, że wartości są unikatowe i jest ich tyle ile wierszy. Jeżeli na kolumnie założone jest ograniczenie CHECK ... IN, mamy pewność, że nie będzie tam więcej wartości niż dopuszczonych przez te więzy integralności. Popatrzmy na poniższy przykład, w którym celowo ograniczyłem możliwości optymalizatora w zakresie szacowania:
CREATE TABLE Computer ( ID int IDENTITY, Name nvarchar(20) NOT NULL ); CREATE TABLE License ( ID int IDENTITY CONSTRAINT PK_License_ID PRIMARY KEY, Name nvarchar(20) NOT NULL, Computer int ); CREATE TABLE N ( N int NOT NULL CONSTRAINT PK_N PRIMARY KEY ); WITH T10 AS (SELECT 1 N FROM (VALUES (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) T(N)) INSERT N SELECT ROW_NUMBER() OVER (ORDER BY (SELECT 0)) FROM T10 A CROSS JOIN T10 B CROSS JOIN T10 C CROSS JOIN T10 D INSERT Computer SELECT N'Computer '+CAST(N AS nvarchar(10)) FROM N INSERT License SELECT N'License'+CAST(N AS nvarchar(10)), N FROM N CREATE INDEX IX_Computer ON License(Computer) INCLUDE(Name)
Teraz popatrzmy na dwa bardzo zbliżone zapytania, JOIN vs. LEFT JOIN:
SELECT TOP 10 H.Name, W.Name FROM Computer W LEFT JOIN License H ON H.Computer=W.ID*1000 SELECT TOP 10 H.Name, W.Name FROM Computer W JOIN License H ON H.Computer=W.ID*1000
Oraz na ich plany wykonania:
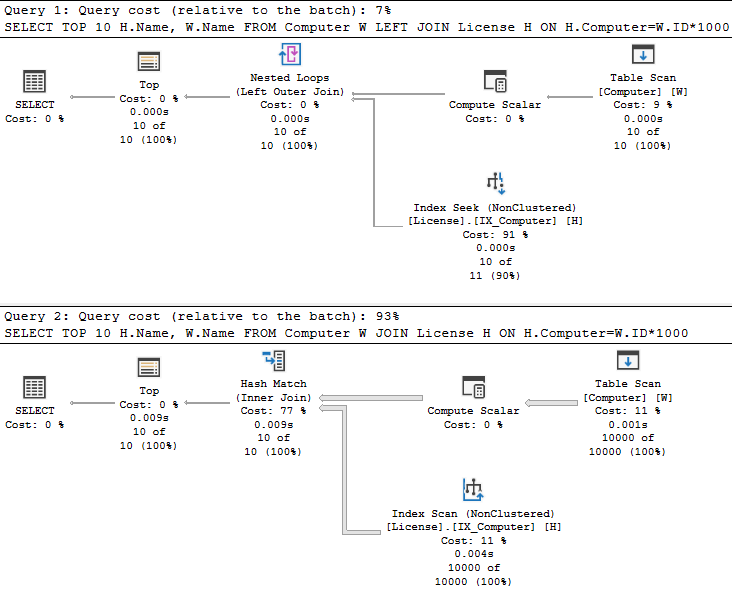
Sam optymalizator szacuje, że JOIN będzie kilkanaście razy bardziej kosztowny (93%/7% ≈ 13,3). Dlaczego tak się stało? Z prostego powodu. Zastanówmy się, ile rekordów z tabeli Computer trzeba przeczytać, aby zwrócić wynik. Maksymalnie 10, bo:
- jeżeli istnieje relacja dołączymy 1 lub więcej rekordów; może to w szczególnym przypadku oznaczać, że do jednego wiersza zostanie dopasowanych 10 rekordów z drugiej tabeli i nie trzeba odczytywać nawet drugiego wiersza z tabeli Computer
- jeżeli nie istnieje relacja, dołączymy NULL, jeden wiersz Computer wygeneruje jeden wiersz wynikowy
Okazuje się, że takiego komfortu nie ma operator JOIN. Ile trzeba odczytać wierszy? 10? A jak nie ma dopasowania? Może 20? A jak te dwadzieścia nie ma dopasowania albo jest tylko jedno? Może 1000? A jak mamy pecha i te dopasowania pojawiają się dopiero dla ostatnich wierszy tabeli Computer? Optymalizator jest zachowawczy i na wszelki wypadek stosuje złączenie typu HASH. Ma ono złożoność liniową, ale wymaga pełnego odczytu pierwszej tabeli i stworzenia dla niej tablicy indeksowanej funkcją skrótu. Inny problem polega na tym, że to złączenie należy do kategorii półblokujących. Pierwsze rekordy mogą się pojawić na wyjściu dopiero po zbudowaniu tablicy z haszowaniem z całej tabeli Computer. Dla porównania plan wykonania LEFT JOIN pobiera jeden wiersz z jednej tabeli, wyszukuje po kluczu wiersz w drugiej tabeli i już! Pierwszy rekord wynikowy jest gotowy!
Podsumowanie
Podstawowa różnica pomiędzy LEFT JOIN i JOIN jest prosta - w przypadku braku dopasowania lewa strona ginie w przypadku JOIN, a uzupełniana jest wartościami NULL w przypadku LEFT JOIN. Dalsze rozważania pokazują, że jeżeli chodzi o samo wyliczanie wyrażenia, sposób łączenia może mieć kolosalne znaczenie. Nie należy jednak nigdy zamieniać JOIN na LEFT JOIN i odwrotnie ze względów wydajnościowych. Złączenie powinno odpowiadać potrzebom wynikającym z logiki biznesowej.
To zgrabnie postawione pytanie "Jaka jest różnica między JOIN i LEFT JOIN?" często pojawia się na rozmowach rekrutacyjnych. Co odpowiedzieć? To zależy, ile mamy czasu...
Kategoria:SQL Server
Komentarze:
Chciałem utworzyć tabele zgodnie z podanym zapisem :
"
CREATE TABLE Employee
(
ID int CONSTRAINT PK_Employee_ID PRIMARY KEY,
FirstName nvarchar(20) NOT NULL,
LastName nvarchar(20) NOT NULL
)"
dostaje komunikat ORA-00907: brak prawego nawiasu ? Co robię żle ?
CREATE TABLE Employee
(
ID number CONSTRAINT PK_Employee_ID PRIMARY KEY,
FirstName nvarchar2(20) NOT NULL,
LastName nvarchar2(20) NOT NULL
)